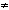 ] for inequality?
] for inequality?(A page from the Loglan web site.)
(From Lognet 96/3. Used with the permission of The Loglan Institute, Inc.)
[Web Editor's Note: This paper has a fair amount of mathematical notation. I've tried my best to render it in HTML, but I'm definitly pushing the boundaries. Please bear with me.]
By Emerson Mitchell
With commentary, and an endnote on MEX, by JCB. Some of JCB's editorial comments precipitated dialogs with the Author, and both Editor and Author decided that you, the Reader, might be interested, and so to leave them in.
A while back there was some technical discussion of the proper syntax for Loglan's identity predicate bi, concerning whether LIP could parse the negation, I think. I forget the conclusion arrived at. The point is that the discussion prompted me to write some general thoughts about identity predicates, Loglan, and Loglan Mathematical Expressions (long-called "MEX"); and JCB has been kind enough to ask me to polish my comments up for inclusion in Lognet. You are looking at the result. Note that this is a general discussion; the opinions expressed are my own and may not be those of The Institute.
The syntax of identity predicates is quite standard. Every formal language I am aware of that has an identity/equality predicate gives it the syntax of a two-part term-relation. That is, whenever <A> and <B> are legal arguments for predicates and/or relations, then [<A> = <B>] is a well-formed sentence [For clarity,I shall be using square brackets for ECM's graphical quotations in this paper.--JCB]. For Loglan this argues that bi should parse like any other two-slot predicate and need not be given special treatment. So why does Loglan treat it differently?
The reason comes from the semantics: What does [<A> = <B>] mean? Formal languages usually give the identity predicate a special role in their semantics that forces [=] to map to the semantic identity--or at least to a special equivalence relation--in all models of the language. What does this mean? First, [=] maps to the semantic identity if and only if (iff) the semantics contain the rule saying that [<A> = <B>] is true exactly when <A> and <B> map to the same object in the model. [Does this mean designate the same object in the world?--JCB] [No and yes. Formal languages deal with special models, not with the real world, and in them we replace designations with formally defined semantics. But designation is the closest thing natural languages have to these semantic-value maps.--ECM] Second, an equivalence relation is any relation which is reflexive (e.g., [x = x]), symmetric ([x = y] implies [y = x]), and transitive ([x = y] and [y = z] together imply [x = z]). A special equivalence relation in the semantics follows the rule that predicates cannot differentiate equivalent objects: if x = y then P(x...) in the model iff P(y...) for all predicates/relations P.
Some philosophers object that this special position for identity should not be a part of the language, but properly belongs in the theories expressed with the language. They have a point, but practically speaking equality is so basic that the language "predicate logic with equality" [What do the last 6 words mean?--JCB] ["Predicate logic with equality" is the major kind of formal logical language used by mathematicians and logicians. I do not really understand what you are asking here.--ECM] [You've answered my question, so maybe, without knowing that you did, you did. One of the strangest things about syntactic ambiguity in natural language--of which those six words were an instance--is that producers of it seldom know they have!--JCB] is the standard formal language for science and mathematics. Loglan has words for both philosophical positions: samto, as an ordinary predicate of identity, and bi, as a special one with its own rules built into the language.
This special semantics for [=] forces some philosophical puzzles. For example [x = x] is always true of anything x that exists, i.e., [x = x] is the predicate of existence, also known as the trivial universally true predicate. [Do you mean that [=] is that predicate, or that [= x] is? [x = x] is, of course, not a predicate but a sentence, and [= x] is not a predicate in the usual sense of that word, but a "predicate expression", i.e., a predicate with one or more of its sutori arguments expressed.--JCB] [I am trying to indicate a reflexive by repeating the variable [x], a standard trick of mathematics. Loglan has better ways of doing this, but I am writing in a mixture of mathematical notation and English, not Loglan. I mean that the predicate formed when both arguments of [=] are filled by the same term with the same referent is the predicate of existence. Lamda notation would be handy, except I don't expect many to understand that either.--ECM]. English reflects this relation in the rules for the verb (to) be, so that the is in X is is the predicate of existence while the one in X is Y is the predicate of identity. (I am aware that English uses X is Y in many senses. The point is that one of the senses is that of equality/identity.) LOD seems to ignore this sense. Look up is in the English-to-Loglan section of LOD: one does not see a reference to bi. [Sorry. There should be one.--JCB] Furthermore, bi not being a preda and having no reflexive prevents our using nuo bi for the existence predicate. [But bi is a predicate! The only reason it is not an allolex of the main predicate lexeme, PREDA, but the eponymous member of a separate lexeme BI, is--if I remember correctly our reasons for creating BI--because we anticipated special roles for bi and kin in the Mathematical Expressions part of the grammar...a part, uuuu, that has not been written yet! As for bi's not being subject to the operations of NU--of which nuo is a member--that can easily be corrected. Shall we? I'm virtually certain we can make *Ba nuo bi parse without conflicts, but we'd better ask our Takrultua, Bob McIvor.--JCB] I suppose the existence predicate is something that only logicians ordinarily use. [The rest of us do ask related questions from time to time. Do you suppose, we wonder about Alice, she of the Wonderland persuasion, that she actually existed? And the answer is, A living model of Dodgson's Alice actually did.--JCB]
These semantic and philosophical features argue for Loglan giving bi a special role, currently reflected in the parser. I don't propose to change the parsing of bi at this late date, but in my opinion, precisely because these special considerations for bi are semantic and philosophical, they should have been handled in the definition and usage rules for bi, not in the parser.
So why does Loglan have Lexeme BI anyway? Why not put all its members into PREDA? I assume there is a history behind this decision, but I am not familiar with it. Is there any reason PREDA cannot have a few little words--for example, bi--for Zipfean reasons? [Words are little "for Zipfean reasons"; words are not members of particular lexemes for such reasons.--JCB] I realize that little words and ordinary PREDAs are distinguished unambiguously by their morphology, but LIP and human parsers alike could handle a small list of exceptional little words in PREDA. [Of course they could; but as I suggested above, the historical reason for keeping the BI Lexeme separate from the PREDA one was mainly anticipatory: it was to make possible the eventual "understanding" of a certain class of sentences called "Equations"--sentences we don't even know how to write yet--for at least we know that these will use bi & kin as their predicates. Note that PREDAs do not work in equations. LIP does not regard 3 + 3 samto 6 as a parsible sentence; it requires us to say Lio 3 + 3 samto lio 6 before it will understand that we are talking about two numbers being "equal", i.e., being identical. But one day we will teach LIP to accept such shorthand equivalents of Lio 3 + 3 samto lio 6 as Te pio te bi so; and LIP will then parse them in either that verbal form or in the even more abbreviated, "symbolic" form that uses numerals, letterals, and mathematical signs instead of phonemic expressions. When that happens written equations like 3 + 3a = 6b/x2 will still be pronounced phonemically, that is, read aloud as their corresponding Loglan words: Te pio teafi bi sobeikuabasuato. It may be only then that the inquiring logli will understand the separateness of the BI and PREDA Lexemes. Indeed it will be only then that they will be playing distinctly different roles in a much larger Loglan grammar.--JCB]
Loglan has an old open problem about Mathematical Expressions, MEX. To me it seems that BI is the start of an incomplete solution to the MEX puzzle. [That it is.--JCB] I think Loglan should drop the MEX attempt altogether. I suggest we admit that mathematical notation is a language of its own, and simply display it as a quoted foreign language. I think we have sufficiently powerful quoting syntax to do this. Loglan would then need ordinary PREDAs for the concepts symbolized, and linguistic PREDAs to refer to the symbols. (This parallels how mathematicians translate their own text among natural languages: we translate the natural language parts and carry the symbolic parts through unaltered. Much of the schoolbook training in mathematics is concerned with learning the language of mathematical symbols.) This reduces the MEX puzzle to its proper position: building words for a specialized scientific jargon. We have a procedure for that.
[Let me respond to Emerson's proposal on the spot. The MEX Project is still justified, I believe, by what it can do for logli numsestua (mathematicians) and their students, not for the rest of us. I, like all other linguistically-trained students of mathematics, have been charmed--indeed, fascinated--by the heroic attempts of mathematicians, often quite unconscious ones, to "linearize" their chalkboard performances in speech. Go to any mathematical lecture, the more abstruse the better, and listen to the odd and cunning usages individual mathematicians have coined to permit them to read off out loud--often fairly accurately--what they have written down in two dimensions on that chalkboard. Loglan MEX, when we have finally forged it, will be that "spoken math". It will be the sort of linearization of "thinking on the plane" that logli numsestua will, at last, be able to speak unambiguously...not only for the benefit of their students, but also, and more productively, perhaps, as a tool of their own creative efforts. Are you charmed by that prospect? So am I. So let's revive this ancient project and give them and us what may well turn out to be a very useful tool.--JCB]
There are some related topics for which I have comments that may be of interest. With apologies to those I am misquoting without attribution, I include these in the form of dialogs.
Don't mathematicians use a single sign [] for inequality?
Yes, we do, but we also use equality compounded with negation [not=]. Most of us think of the inequality symbol as an abbreviation of that compound. So we do need to negate bi somehow, saying things like not(a = b) iff (a not= b) iff (a b).
Loglan must accept the compound predicates that involve identity along with bi/cie/cio. We must make the parser accept ciebi/ciobi/noicie/noicio as well as noibi. [I'm not certain what works best as the negative prefix, here: noi- or no-. If /no/ in such contexts always precipitates correct compounding, then we should use nobi, nocie, and nocio; if it doesn't, then these noi-words are best (-noi is always required as the negative suffix (as in anoi), of course).--JCB]
Consider the current members of BI: bi bia bie cie cio, etc. From the standpoint of modern logic, these are all "two-term relations", that is, relations that relate two referring terms. For use in mathematics, this list is orders of magnitude short of the number of term relations needed. There are not enough potential little words in Loglan to do the job. Conversely, for the logician, the only difference between ordinary predicates and BI-type predicates is the notational sequence of their elements. We say x = y for term relations but P(x,y) for ordinary two-place predicates.
Don't formalists need a "time-inflected" sense of the identity operator?
Generally speaking we don't, and when we do, we invent special symbols. What formalists do for a living is work with small "formal languages". Because these are only formally defined, they are outside natural languages altogether. It is a mistake to import formal language considerations into Loglan unless Loglan has a natural need for them.
One day we will get around to writing the MEX portion of our grammar, where such talk will figure prominently. We will not drop the MEX project. We need to distinguish between contexts where numbers are equated to each other and those where they are used to quantify predications. [In this remark I recognise an echo of myself, soi crano.--JCB]
Have we even gotten so far as to define the purpose and scope of the MEX portion of our grammar? I take your point about the different contexts for the numbers, "equational" versus "non-equational", but cannot remember what else is in the scope of MEX. For example, I think one requirement should be that arbitrary displayed formulae should be readable in Loglan. Which means that I see a dilemma: either treat displayed formulae as unparsed strings of words within special delimiters so LIP can pass over them as a chunk, or include essentially all the syntax possible in current scientific literature. Ouch. ["Passing over them as [unparsed] chunks" is essentially what LIP does now. LIP views any mathematical sign--except bi and kin--as a NI, and then collapses any string of NIs into a single NI. This means that any string of numerals, math signs, and letterals preceded by numerals, is simply a NI, a number whose insides remain unparsed. That's not good enough for the eventual Loglan Understander, of course, who will want to know what Efi bi meiceisuato--writable as [e = mc![]() 2] or [e = mc2]--means.--JCB]
2] or [e = mc2]--means.--JCB]
Hue Djeimz Kuk Braon:
With his last remark, Emerson invites me to raise the Mathematical Expressions Project from the dead, soi clafo. I'll try. If I succeed, I'll be able to invite other mathematically-trained logli to join me in its broad precincts... especially those younger than myself who have a feeling for, or would be interested in learning about, the linguistics of mathematical speech. To any such younger worker, I would gladly turn the Project over entire! For I regard it as one of my most important roles these days to motivate other people to restart our stalled projects.
E asks, has the "purpose and scope" of the MEX Project ever been set down? Yes. There are numerous letters, notes, and articles in early issues of The Loglanist (TL) that collectively do just that. Our "archivists"--those of us older members who received and kept these early TLs, or those post-'89-ers who bought, and presumably read, the whole "in-print set" of them when they joined (the number of TL issues ever printed was 21; those currently in print are nine; the early birds got the whole 21)--will know where to find them. But if memory serves, our goals in writing the MEX portion of Loglan grammar were to produce both
Let's take the linearization goal first. Many chalkboard expressions are two-dimensional arrays: graphemes rise or fall as well as proceed from left to right as the mathematician writes them on the board. Examples are integration [![[integral sign]](integral-glyph.gif) ], summation [
], summation [![[capital sigma]](cap-sigma-glyph.gif) ], long fractions, exponents [2n], radicals, and subscription [x1]. To speak such non-linear arrays, one must first linearize them (speech is ineluctably linear). One solution is to use spoken "up" and "down" signs, such as sua to the power... and rea to the root..., and to represent them by up-arrows [
], long fractions, exponents [2n], radicals, and subscription [x1]. To speak such non-linear arrays, one must first linearize them (speech is ineluctably linear). One solution is to use spoken "up" and "down" signs, such as sua to the power... and rea to the root..., and to represent them by up-arrows [![]() ] and radical signs [
] and radical signs [![[square root]](square-root-glyph.gif) ] in the linearized text. Such "lifting" graphs may be occasionally matched with down-arrows [
] in the linearized text. Such "lifting" graphs may be occasionally matched with down-arrows [![]() ], pronounced suo, but only when the raised portion of the array is non-final in its "equation half", that is, when the raised element doesn't terminate either the right- or the left-half of some equation. Thus, tosuanei [2
], pronounced suo, but only when the raised portion of the array is non-final in its "equation half", that is, when the raised element doesn't terminate either the right- or the left-half of some equation. Thus, tosuanei [2![]() n], if final in its half (as it is in Da bi tosuanei [X = 2
n], if final in its half (as it is in Da bi tosuanei [X = 2![]() n] requires no final down-arrow; but tosuaneisuoafi, in which the lifted nei is not final in either half (as it isn't in Teda bi tosuaneisuoafi [3X = 2
n] requires no final down-arrow; but tosuaneisuoafi, in which the lifted nei is not final in either half (as it isn't in Teda bi tosuaneisuoafi [3X = 2![]() n
n![]() a]), does require that this "descent to the base-line" for the element [a] be spoken. So we write the linearized form of [2n] as [2
a]), does require that this "descent to the base-line" for the element [a] be spoken. So we write the linearized form of [2n] as [2![]() n], of [2na] as [2
n], of [2na] as [2![]() na], of [2na] as [2
na], of [2na] as [2![]() n
n![]() a], and of [2an] as [2a
a], and of [2an] as [2a![]() n] . Back-mapping these linear expressions onto non-linear arrays, that is, into genuine chalkboard expressions, will--if we are successful in writing this essentially graphical grammar--always be one-to-one. Thus, tosuaneisuoafi could still be written [2na] two-dimensionally as well as [2
n] . Back-mapping these linear expressions onto non-linear arrays, that is, into genuine chalkboard expressions, will--if we are successful in writing this essentially graphical grammar--always be one-to-one. Thus, tosuaneisuoafi could still be written [2na] two-dimensionally as well as [2![]() n
n![]() a] linearly, and tosuafo, whenever final in its half, could be printed [24] in text or linearly as [2
a] linearly, and tosuafo, whenever final in its half, could be printed [24] in text or linearly as [2![]() 4], however we choose to instruct the printer.
4], however we choose to instruct the printer.
This only scratches the surface, of course, of the vast topic of linearization. But I trust it will suggest the breadth of the solution-pathways that are waiting to be explored.
Now for depth minimization. In a famous article written in the early 1960s, Victor Yngve, a computational linguist then at MIT, introduced the idea of "grammatical depth" to the computing community...thus becoming (along with Quine, Whorf, Chomsky, and a great many unknowing others, soi crano) one of the intellectual "fathers" of Loglan. (L is, of course, a multipaternal offspring...an unworkable arrangement in nature but quite common in the ideonic world). Yngve defined depth (I paraphrase from memory) as the maximum load on the temporary memory of any speaking/listening device that is "experienced" by it during the production or understanding of some utterance, that maximum load to be taken as the largest number of elements that must be held in memory by that device while producing or understanding that utterance. The depth concept is computationally explained--with diagrams, I believe--in one of my early TL articles on the development of Loglan grammar; for Yngve's model was my beacon during most of that development. And, of course, Y's original (1961) article (see the reference to it in the Bibliography of L1) should be consulted by those wishing to pursue depth more deeply.
Now, the subjective manifestation of the "grammatical depth" of a sentence, when excessive, is discovering, when you are midway in its production, that you can't finish it! Or, while listening to some lecturer's excessively "nested" discourse, to discover in the middle of one of lei's sentences that you've "lost it"...that you've actually failed to parse it as it went by. Ordinary speakers and listeners find themselves in this sort of grammatical "deep water" only rarely, while lecturers on abstruse topics, and habitual goers to such lectures, learn to avoid these high-depth regions of speech like the plague. That is, as lecturers they learn to limit the grammatical depth of their utterances as a courtesy to their listeners--more than courtesy, as a condition of anyone's understanding them!--and as listeners, to drop the classes of those lecturers who don't take this kind of minimal pity on their listeners. As all academics are both sometime lecturers and sometime lecture-goers, we university denizens know these depth phenomena personally and well.
But one of the most striking points made by Y in his 1961 paper was how much depth we can and do tolerate in algebraic expressions--load peaks of as much as 12 or 15 elements in memory are apparently not unusual--and how little depth we do, or even can, tolerate in spoken utterances...never more than 7, Y hypothesizes. That is, in fact, the "hypothesis" alluded to in the title of Y's paper. A possible reason for this striking difference in "tolerable depth", Y shows, is simple. Algebraic expressions are not only non-linear, but unlike spoken ones, they are frozen in time. So the hopeful understander of a chalkboard equation can scan it backwards and forwards, up and down, along this diagonal or that one, or make u's attention jump around at will in it, and u may do this as many times as u likes while letting understanding gradually sink in...at least until the impatient professor sweeps it from the board! So our MEX project cannot be to make the linear transformations of such essentially high-depth, two-dimensional arrays as low in depth as ordinary speech is! They can't be so transformed. But if we have a choice between two notational routes to linearization--and in designing our MEX notation, we often do have such choices--we should examine them both for their effects on depth, and then choose the one that generates the least amount of it.
Here's a simple chalkboard example: [(a + b)2]. How would you read such an expression aloud? Most E-speaking math teachers will read this one as Eigh plus bee, the quantity squared. Now it happens that this way of speaking generates reasonably low depth. The depth of Eigh plus bee, the quantity squared is much lower, for example--much easier on listeners who cannot see the board--than saying Open-parenthesis, eigh plus bee, close-parenthesis, squared. The principle is a familar one...Loglan grammar is riddled with it. If you can get the machine to insert some "missing marker" accurately, do so; don't say it yourself. Get the machine to infer that "you meant to say it" but didn't bother, and let m put it in for you while m is trying to parse what you said. Machines can perform this elegant service for us, we discovered during the MacGram years; and interestingly enough, letting them do so actually reduces the burden of understanding on the listener. The "machine" here, of course, is the human listener, the math student. And on being told Eigh plus bee, the quantity squared (assuming s can't see the board) s will first write [a + b)2] in left-to-right sequence in s's notebook just as s hears it, and then go back--remember, s can go back to fix up non-linear arrays, for they are essentially free of the urgencies of time--and insert the "missing left parenthesis". That done, a perfect, two-dimensional transcription of the sense of Eigh plus bee, the quantity squared results, namely [(a + b)2].
There's more, of course. But I will let you invent other depth-minimization ploys if you want to take up this work. And I strongly urge any of you mathematics-lovers out there who also have a feel for language--and that could well be all of you; for after all, you're logli!--to at least have a go at writing a grammar for MEX...and show us your results.
I thank our mathematical logician, Emerson Michell, for challenging me to explain the value of--and thus possibly revive--this oldest of our stalled projects.
--Hue Djimbraon
Copyright © 1996 by The Loglan Institute, Inc. All rights reserved.
Send comments and corrections to: